ARABIC CONCORDANCES
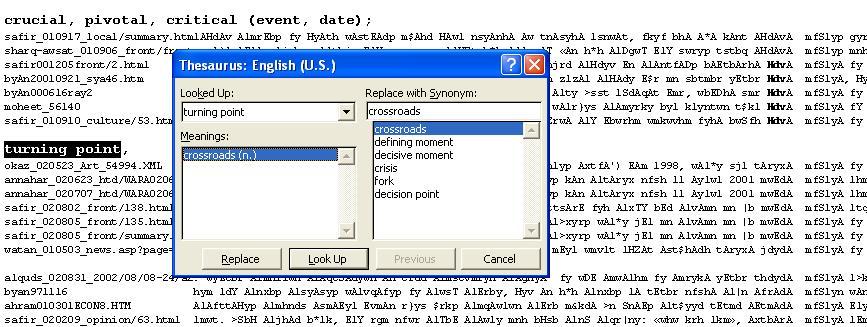
I experimented over several years with various KWIC layouts for Arabic, using Arabic script and transliteration, monitors of various sizes and resolutions, plain text and formatted text, ASCII editors, Excel, IE and Word. After many trials I settled on a configuration using Word RTF files and transliteration, which allows me to display over 226 mono-spaced characters per line: I usually allocate 30 for the reference, 96 for the context before the KWIC, and 100 for the context that follows it. The font I use is set to a point size of 7, and the zoom view in Word is set at 112%. These settings and two tab stop values are all in the RTF file header, which I generate automatically along with the concordance output. By using Word file format for my concordances I can start composing my dictionary entries in the concordance file itself. As I identify the different lemmas, senses and collocations, I sort and re-group them by cutting and pasting the concordance lines directly. When I type in tentative translation equivalents I can also make use of Word's thesaurus (102k).
Regular expressions for extracting citations from a corpus need to specify the optional short vowels and diacritics. (Although most hits will have no short vowels or diacritics, those that do are usually interesting hits, so it's often worthwhile to include optional short vowels and diacritics in one's search, even though it slows down searching tremendously). A search for the noun stem fltAn, for example, is specified as:
/(^|[^$alpha])[$vds]*[wf]?[$vds]*([blk]?[$vds]*|[bk]?[$vds]*A[$vds]*l[$vds]*|[blk]?[$vds]*h[$vds]*A[$vds]*l[$vds]*|l[$vds]*l[$vds]*)f[$vds]*l[$vds]*t[$vds]*A[$vds]*n/
where $alpha = PJG'|>&<}AbptvjHxd*rzs$SDTZEg_fqklmnhwYyFNKaui~o
and $vds = aiuo~_NFK (Here is a page with my Transliteration).
Here are two versions of the same concordance prior to editing:
concordance of fltAn sorted by text after the KWIC: fltAn-A.rtf (356k)
concordance of fltAn sorted by text before the KWIC: fltAn-B.rtf (356k)
Collocations readily show up in both versions:
in fltAn_A: (N+Adj) fltAn Amny, fltAn AxlAqy, fltAn AElAmy; (idafa) fltAn AlAmwr, fltAn AlAsEAr, fltAn AlwDE AlAmny; (misc. phrases) AlfltAn wAltsyb, AlfltAn wAlfwDY; (proper noun) AlfltAn bn EASm
in fltAn_B: (idafa) HAlp/HAl AlfltAn, DbT AlfltAn, mnE AlfltAn; (misc. phrases) Altsyb wAlfltAn, wDE Hd llfltAn, AlfwDY wAlfltAn; (idiom) flAn Aw fltAn
And here is a sample concordance with re-arranged lines and inserted temporary glosses (i.e., this is lexicography in progress): mfSly-B.rtf (562k).
HOME | CORPUS COMPILATION | WORD FREQUENCY COUNTS | CONCORDANCING | MORPHOLOGY ANALYSIS | ARABIC LEXICON
Copyright © 2002 QAMUS LLC
{kind=link}